12 Jul 2020 /
Sarah Crossing

A summary and observations from Dr Stephen Wan's session at Students First 2020. Lead scientist at CSIRO's Data61 (and leading the CSIRO-Studiosity project starting in 2020) Dr Wan takes us back through an engaging and practical explanation of the history of AI through the 90s, 00s, and now, before explaining the reality and opportunities for personal study help and the student experience in universities.
There are two immediate opportunities for AI and personal learning
1. Learn from AI advances and challenges over past decades.
2. Help the people who are helping students.

When asking 'how' can AI help - instead let's ask, 'who' can AI help?
Where personal interaction, sense of belonging to a community, and responsibility for advice given are important, then AI's role should be to help people. Or, as Dr Wan puts it:
"The goal is to learn to write better, not to automatically correct all of the errors in a text."
A student needs writing help, and the online tutor - the online specialist - can be likewise helped to better, and more quickly, facilitate that learning process, too.
"If you've ever had to proof read a student's writing, you'll know how hard it is to walk that line of simply correcting text on their behalf and versus presenting the feedback in a format that they can use to take the next steps to improve their own writing."
The post-COVID race relies on pre-COVID learning
Why 'productivity tools' as opposed to fully automated solutions with AI?
It is now more critical to help teachers create connections with their students remotely, and likewise help online support staff help students more efficiently, in greater numbers than ever before,
"It would certainly seem that in our post-COVID world, online delivery of these services is going to be a key strategy."
Aside from core needs of belonging and engagement, Dr Wan notes that research to date has shown us that a fully-automated solution is simply not on the horizon, at least functionally. Discussion in recent years also suggests that AI in learning is neither up to standards acceptable to student satisfaction, nor yet desirable to educators. One such observation was made by Prof Chris Tisdell.
Current options and why they still fall short
Dr Wan starts by breaking down the problem at hand - the online specialist has to read the students work, understand it, mark it up, and provide clear feedback efficiently for the student to act on.
So let's say there is a missing comma. This might be one area for machine learning to notice, mark, and provide feedback on, leaving the specialists to consider high-order, personalised feedback for the student.
If there are several auto-grammar checking tools already available - Dr Wan references the work of Grammarly - then why does this still need as much consideration as lead scientists and developers at CSIRO and Studiosity are giving it?
Benchmark datasets (where known grammar errors are drawn from) and biases are important here. This is where the AI history lesson comes in, explained like a fairy tale: Once upon a time in the 90s, machine learning boomed...
Benchmark datasets are huge quantities of data like that of Google's Web 1T 5-gram data corpus in 2006.
"This dataset gives statistics of word sequences of up to five words at length, where these statistics are drawn from web text as a proxy for reasonable language use."

Huge quantities of data means that probabilities can be calculated with more accuracy - based on millions of data points, combinations of words in sentences, one 'correction' is deemed to be more likely than another, and that is presented to a user.
Breaking it down for his audience, Dr Wan uses 'the cat sat on the mat' as an example. A translation tool can take this sentence from English to German using previous datasets and probabilities of which word can be replaced, where.
"My language model can tell me that those three words in sequence, "die Katze sitz" is more probable than any other alternative that the translation system might be considering at the time. So the way that these machine learning algorithms work for translation is that they see thousands upon thousands of these pairings of sentences with this sample translations, and they simply memorise which words in English match to the corresponding word German. And under which contexts these mappings are valid."
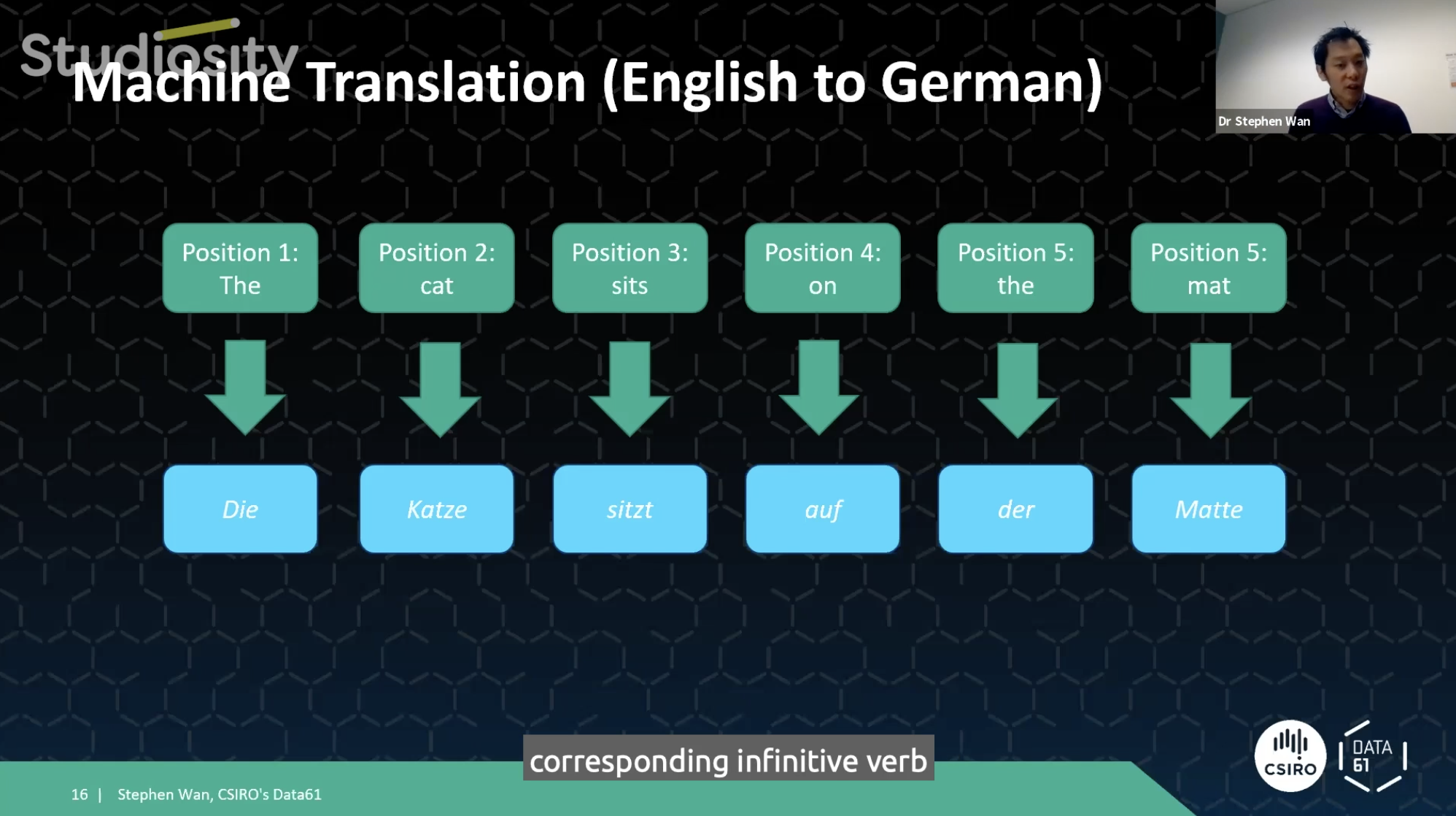
So instead of translating English to German, Dr Wan explains that machine learning applies the same process to checking grammar. Taking an incorrect sentence and trying to turn it into a correct one.
"The language model can tell us that the three words "the cat sits" is more probable than the three words, "the cat sit". And if you compute these probabilities using large datasets for English...you quickly end up with a potentially a viable solution to grammatical error correction."
Do we have newer datasets now? Yes, English learning centres at universities are a recent source of rich, writing corrections.
"Four out of the six benchmark datasets had a focus on ESL writing, including the 2019 dataset. This is probably due to the availability of this kind of data and the strong links that the computational linguistics research community have with organisations that run English testing. But needless to say, if you're providing a feedback service, this should cater to all kinds of students, not just the ESL students. If your dataset only represents ESL writing, you introduce a bias in your data error and grammatical error detection system."
Further, Dr Wan introduces us to BERT, which is "based on masses of text that you find in Google Books and Wikipedia." It is designed to capture correct English. But which isn't based on masses of undergraduate student writing. It doesn't discount their usefulness, but forces the Data61-Studiosity project team to be more open-minded.
The goal is to learn to write better
"In my earlier example of "the cat sits on the mat", there was, of course, another alternative correction, and that is the "cats", plural, "sit on the mat". And this introduces all kinds of methodological issues with adopting machine translation approaches for grammatical error correction."
So there are limitations to auto-correct tools. Technically, practically, and ethically, it begs a question. Should the direction of academic machine learning be trying to improve auto-correct features - or should work go in a more innovative direction, toward error-detection, requiring a student to notice and act?
At the core of Studiosity's service is formative feedback - where action is required of the student. Conversely, it is the problem with automatic grammar-checking tools, which offer at best passive auto-corrects, or at most dangerous, academic dishonesty.
Current standards within Studiosity are more granular, specific
"You can see that the Studiosity error types are more fine grained than the academic dataset and the academic dataset just lumps all the punctuation errors together into one category.
If we were to use the 2019 dataset - from the academic dataset - to build a grammatical error detection system, we might determine that there was an error in the sentence and the system might work out which part of the sentence the problem.
But all it can then do is say there is an error *here* and it's related to punctuation and doing so, just saying that it's a punctuation error might not be so helpful if you consider the earlier examples of Studiosity's writing feedback. The tutor was pointing out specific kind of problem to do with a comma and the fact that it was something to do with introductory phrases. So the key thing to learn here is that the granularity of the grammatical error types that we need to have in the dataset, these need to be appropriate for our writing feedback application."

Where to next for advances in formative feedback, AI, and ethical student learning?
In his measured, considerate delivery, Dr Wan helped us realise:
- Work with AI in education needs to acknowledge the successes and limitations of datasets and work that has come before.
- To improve a student's writing, the dataset needs to be representative of students who need to improve their writing.
- A grammatical, detection tool will be a time saver. Allowing the specialist to offer more comprehensive feedback elsewhere, which may mean less time spent overall on each student interaction, or indeed the same time, with more value delivered as confidence and student satisfaction.
Last but not least, user experience should be at the centre, for both the specialist and the student.
"Think about what the tutor has to do. They have to choose what's appropriate at that particular time to help the student and choose how best to wrap that message up to to give to the student. And that's that's a really complex task."
Likewise for students, taking on board feedback in a measured, natural - non-overwhelming way - and in a way that promotes academic honesty and literacy, is critical for any student, but particularly for first-year, first-in-family, and other non-traditional university students.
Otherwise, a great piece of AI might be incompatible with the student's process of absorbing feedback, and the specialist in providing it; and therefore lack large-scale, real-world application, and social impact. The Studiosity - CSIRO-Data61 project will produce all of the above.
Thank you to Dr Stephen Wan for your computational linguistics, machine learning, data history session (and lesson.) If you're interested in how this will change your own - or your university's Studiosity service, drop us a line.
Next: For all things personalisation, advancing technology, and formative feedback:
Watch Dr Stephen Wan's full Symposium 2020 session, here
Read Denise Stewart's observations and goals for the CSIRO-Data61 and Studiosity project, here.
Formal details of the partnership and project, are here.